以下是一些已经被广泛研究的标准机器学习任务:
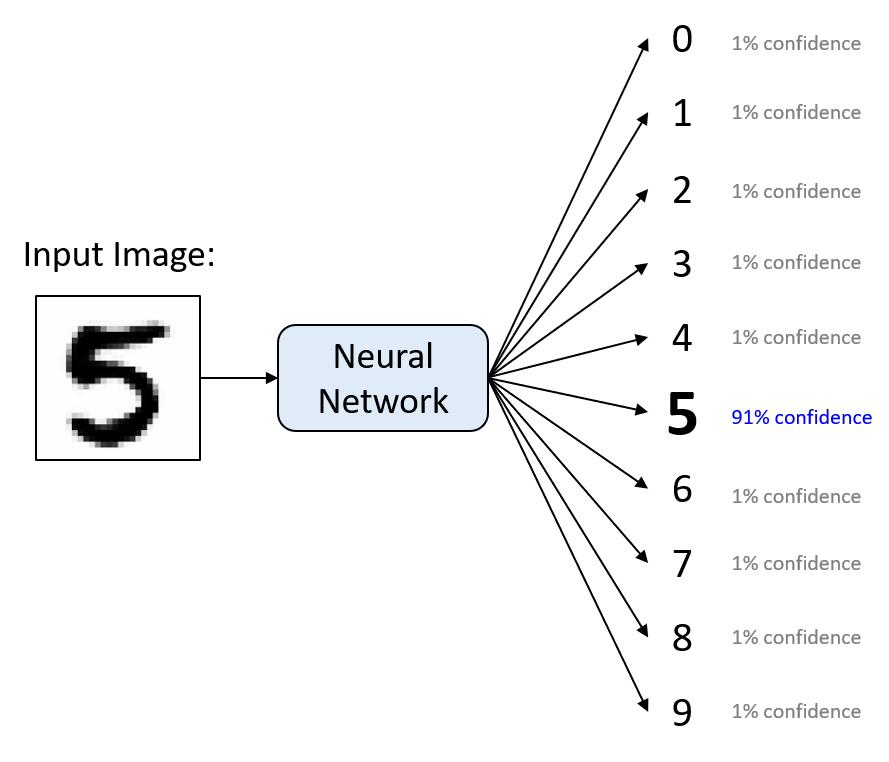
- 分类:这是给每个项目分配一个类别的问题。
- 文档分类包括将每个文档分配到政治、商业、体育或天气等类别
- 图像分类包括将每个图像分配到汽车、火车或飞机等类别
- 这类任务中的类别数量通常少于几百个,但在一些困难任务中可能要大得多,甚至像OCR、文本分类或语音识别中那样是无限的。
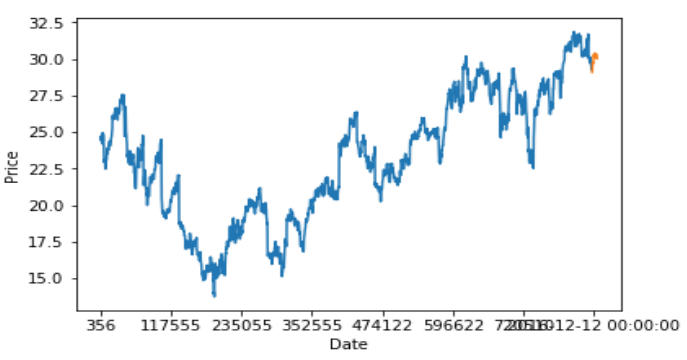
- 回归:这是为每个项目预测一个实值的问题。
- 预测股票价值或经济变量的变化
- 在回归中,错误预测的惩罚取决于实际值和预测值之间的差异大小
- 分类问题不同,在分类问题中通常没有类别之间的接近性概念。
- 分类问题不同,在分类问题中通常没有类别之间的接近性概念。
- 排序:这是根据某些标准学习对项目进行排序的问题。
- 网络搜索,返回与搜索查询相关的网页
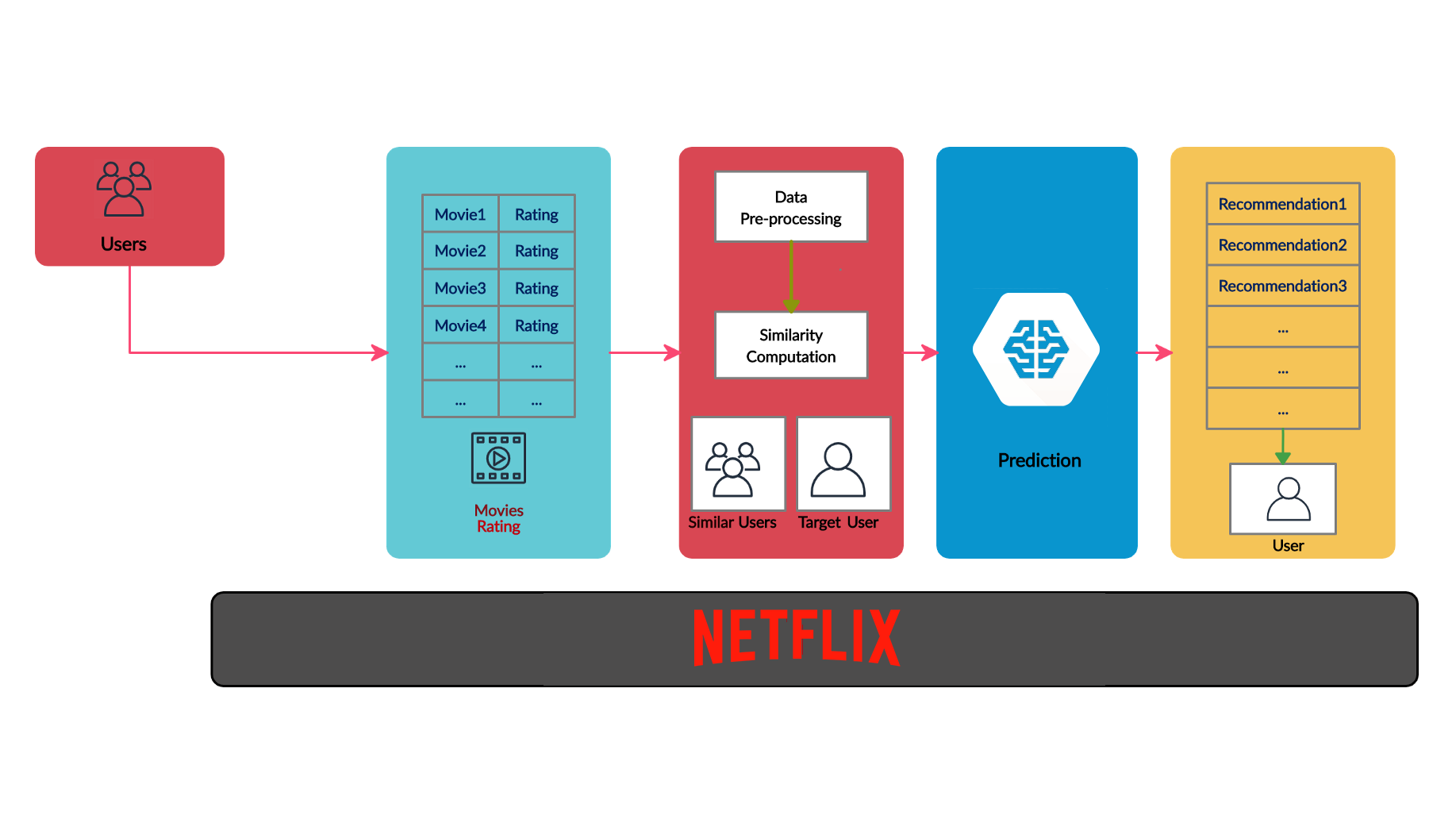
- 网络搜索,返回与搜索查询相关的网页
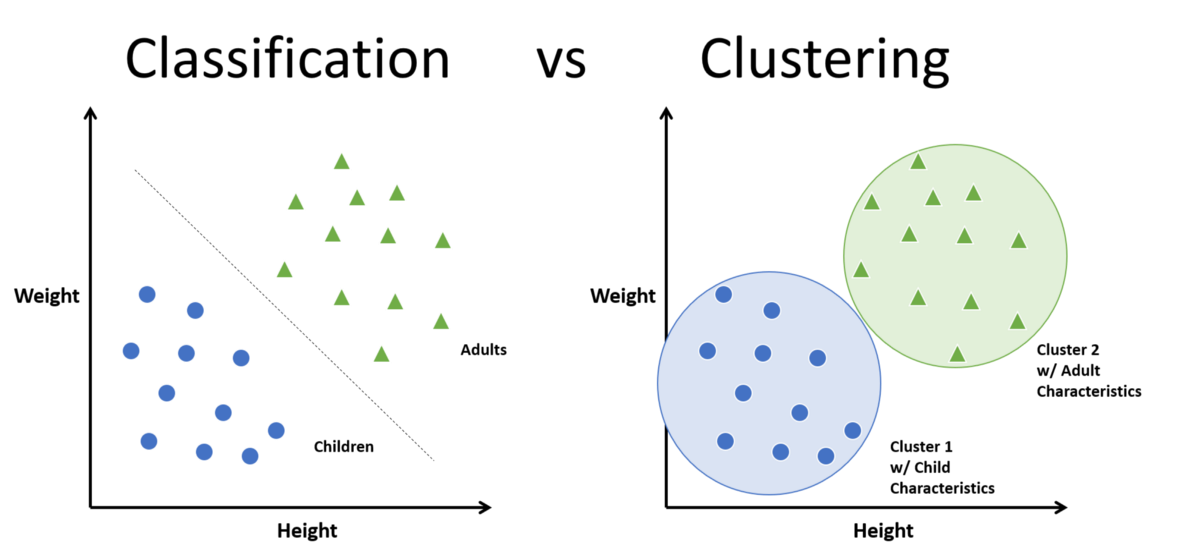
- 聚类:这是将一组项目分割成同质子集的问题。
- 聚类通常用于分析非常大的数据集。
- 例如,在社交网络分析的背景下,聚类算法试图在大型人群中识别自然社区。
- 维数降低或流形学习:这个问题包括将项目的初始表示转换为一个低维表示,同时保留初始表示的一些属性。
- 在计算机视觉任务中预处理数字图像。
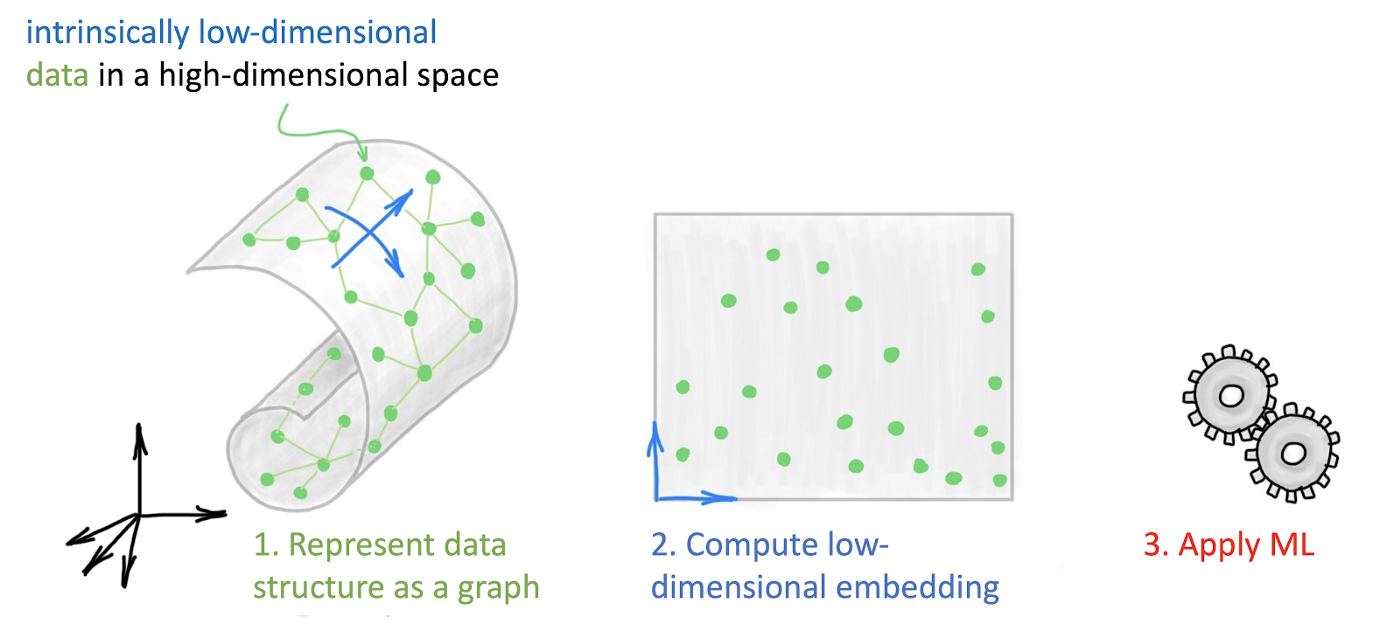
- 在计算机视觉任务中预处理数字图像。
机器学习的主要实际目标包括
- 为未见过的项目生成准确的预测
- 设计高效且健壮的算法来产生这些预测,即使对于大规模问题也是如此
一些基本问题包括:
- 哪些概念族实际上可以被学习?
- 在什么条件下,这些概念在计算上可以学习得多好?