简要描述一些常见的机器学习场景:
- 监督学习 (supervised learning):
- 学习者接收到一组标记过的例子作为训练数据,并对所有未见过的点进行预测。
- 这是与分类、回归和排名问题最常见的情况相关的场景。
- 上一节讨论的垃圾邮件检测问题就是监督学习的一个实例。
- 无监督学习 (unsupervised learning):
- 学习者仅接收到 未标记 的训练数据,并对所有未见过的点进行预测。
- 由于在一般情况下该设置中没有标记的例子可用,因此可能很难定量评估学习者的性能。
- 聚类和降维是无监督学习问题的例子。
- 半监督学习 (semi-supervised learning):
- 学习者接收到一个由标记数据和无标记数据组成的训练样本,并对所有未见过的点进行预测。
- 半监督学习常见于无标记数据容易获得但标签获取成本高昂的场景。
- 应用中出现的各种类型的问题,包括分类、回归或排序任务,都可以视为半监督学习的实例。
- 希望学习者可访问的无标记数据的分布能帮助他比在监督学习设置中取得更好的性能。
- 分析在何种条件下可以实现这一点的条件是现代理论及应用机器学习研究的热门话题。
- 转导推理 (transductive inference):
- 与半监督场景类似,学习者接收到一个标记训练样本以及一组无标记测试点。
- 然而,转导推理的目标仅是对这些特定的测试点预测标签。
- 转导推理似乎是一个更简单的任务,与现代各种应用中遇到的场景相匹配。
- 但是,与半监督设置一样,在这个设置中实现更好性能的假设是尚未完全解决的研究问题。

- 在线学习 (on-line learning):
- 与之前场景不同,在线场景涉及多轮,其中训练和测试阶段相互混合。
- 在每一轮中,学习者接收到一个无标记的训练点,进行预测,接收到真实标签,并承担损失。
- 在线环境中的目标是最小化所有轮次的累积损失,或者是最小化遗憾,即实际累积损失与事后最佳专家的损失之差。
- 与刚刚讨论的前几个设置不同,在线学习没有做出任何分布假设。
- 实际上,在这个场景中,实例及其标签可能是被对抗性地选择的。
- 强化学习 (reinforcement learning):
- 在强化学习中,训练和测试阶段也是相互混合的。
- 为了收集信息,学习者主动与环境互动,并在某些情况下影响环境,每次行动都会获得即时奖励。
- 学习者的目标是通过对行动和与环境的迭代来最大化他的奖励。
- 然而,环境不会提供长期奖励反馈,学习者面临探索与利用的困境,因为他必须在探索未知行动以获取更多信息与利用已收集的信息之间做出选择。
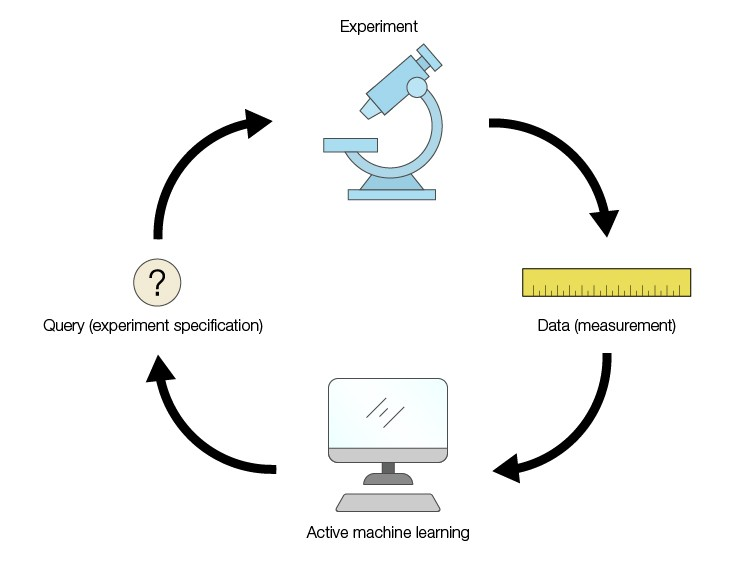
- 主动学习 (active learning):
- 学习者自适应地或交互式地收集训练示例,通常通过询问一个预言机来请求新点的标签。
- 主动学习的目标是以比标准监督学习场景(或被动学习场景)更少的标记示例实现相当的性能。
- 主动学习通常用于标签获取成本较高的应用,例如计算生物学应用。